Nov 05, 2024
Apache HugeGraph 内存管理框架的设计与实现
笔者在 2024 年有幸参与了 Apache HugeGraph 的内存管理工作,从 0 到 1 搭建了 Apache HugeGraph 对于 Query 的内存管控。
对于一个 Java base 的系统,堆内存全部是由 JVM 以及 GC 进行管控。本项目的难点和亮点在于,在 JVM 的框架下对内存进行灵活的分配、去配以及监控管理,实现更加个性化、精细化的内存调控。
具体来说,Apache HugeGraph 的 Query 链路可能有极大的负载,导致某些时间窗口内,内存使用压力极大。
- 如果使用堆内存,依赖 JVM 进行管控的话极易因为 Full GC 造成不可控的 stw 从而影响所有链路的业务。
- 我们希望减少 Full GC 的影响,并且即使内存不足,也不要 stw 影响全部链路的业务。可以通过暂时 hang 某一条链路从而保证其他业务的正常进行。
- 使用 JVM 原生的内存管控框架无法实现细粒度的内存调控
- 我们希望对于各种细粒度的内存分配、去配都能白盒管理,并辅助对全局业务流进行调配,从而保证系统的稳步运行而不是卡死。
为了解决上述问题,我基于堆外内存、零拷贝序列化、树形层次式内存管理架构等角度提出了解决方案,并合入了 Apache HugeGraph 的主分支。
本文档为中文版,原版文档可以参考:https://github.com/apache/incubator-hugegraph/wiki/%5BMemory-Management%5D-GSoC-2024-Final-Report
Project Overview
To reduce request latency and response time jitter, the hugegraph-server graph query,engine has already used off-heap memory in most OLTP algorithms. However, at present, hugegraph cannot control memory based on a single request Query, so a Query may exhaust the memory of the entire process and cause OOM, or even cause the service to be unable to respond to other requests. Need to implement a memory management module based on a single Query.
Key goals includes:
- Implement a unified memory manager, independently manage JVM off-heap memory, and adapt the memory allocation methods of various native collections, so that the memory mainly used by the algorithm comes from the unified memory pool, and it is returned to the memory pool after release.
- Each request corresponds to a unified memory manager, and the memory usage of a request can be controlled by counting the memory usage of a request.
- Complete related unit tests UT and basic documentation.
Feature Implemented
Feature1: Hierarchical Memory Allocation
Design:
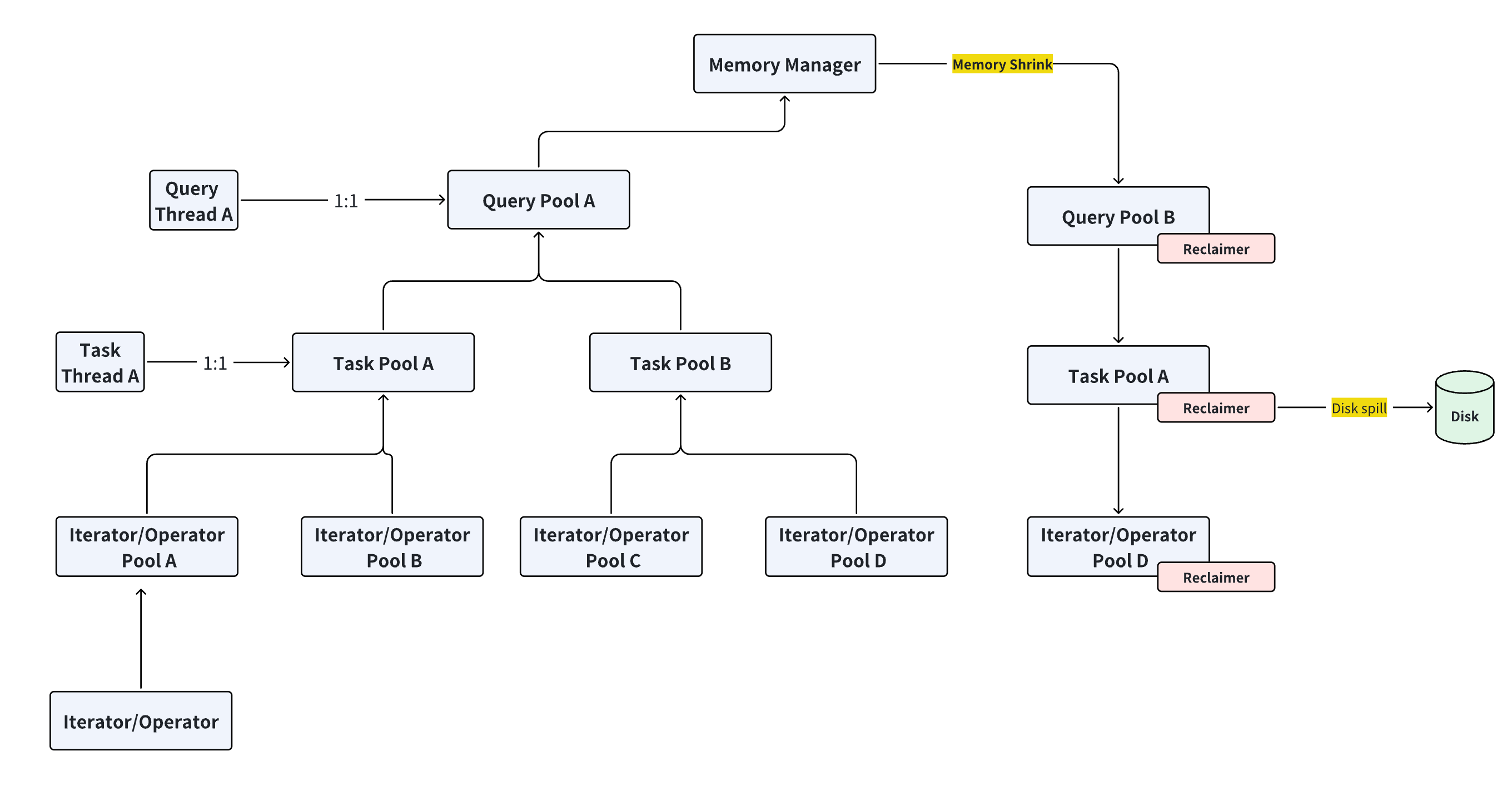
如上图所示,对于不同层次的执行组件,我们分配不同层次的 MemoryPool(MemoryContext),分别对应管理。
每个 Query 对应一个 QueryMemoryPool
一个 Query 派生出的每个 Task(每个线程),对应一个 TaskMemoryPool
一个 Task 使用的每个 Operator(如 HG 中的各种迭代器),对应一个 OperatorMemoryPool
MemoryManager 管理所有的 MemoryPool
生命周期相近的对象尽量放在一个 MemoryContext 里,访问的时候不跨物理内存,释放时一起释放
通过这种方式,我们可以实现对每个查询任务的内存实际使用量的精细追踪,精确到运算符级别。这样,对于全局的内存使用和控制便能达到最佳效果。
以上三种 MemoryPool 可以组成一个 MemoryPoolTree,根节点是 MemoryManager,叶子节点是 OperatorPool
真正需要使用内存的是叶子节点 OperatorPool
上层的 TaskPool 和 QueryPool 本质上不申请使用内存,它们作为聚合池,把底层叶子节点的使用情况聚合起来。并且作为管理子池的生命周期。
内存池的生命周期:
QueryMemoryPool:每个 query 请求入口处创建,如 http query 请求。query 结束时 release,并释放对应内存
TaskMemoryPool:每当 Submit 一个新线程任务时创建,如 Executor.submit(() -> doSomething())。线程任务结束时 release,并释放对应内存
OperatorMemoryPool:每当创建一个 Iterator 时创建,不主动 release,只有当上层的 TaskMemoryPool release 时触发自己的释放。
Effect:
Feature2:按需内存分配
Design
所有的内存分配请求都由叶子节点 OperatorPool 发起,向上传递使用量,自底向上传递到 QueryMemoryPool
- 由 QueryMemoryPool 处统一消耗 MemoryManager 的内存。
- QueryMemoryPool 有容量限制,如果容量不够,会向 MemoryManager 申请内存
- 先进行逻辑申请内存 requestMemory 操作,再进行真实物理分配 allocate。request 逻辑完成后,MemoryManager 和 Pool 中的各统计信息就会发生改变。
如果 QueryMemoryPool 的内存足够,会返回分配结果,分配结果自顶向下逐层返回到叶子结点
如果 QueryMemoryPool 的内存不够,会向根节点 MemoryManager 请求一次内存仲裁
每次分配的内存采用「预留」策略,借助量化机制,减少申请次数。如果申请的 size:
< 16MB,按照 1MB 的粒度向上取整
< 64MB,按照 4MB 的粒度向上取整
>= 64MB,按照 8MB 的粒度向上取整
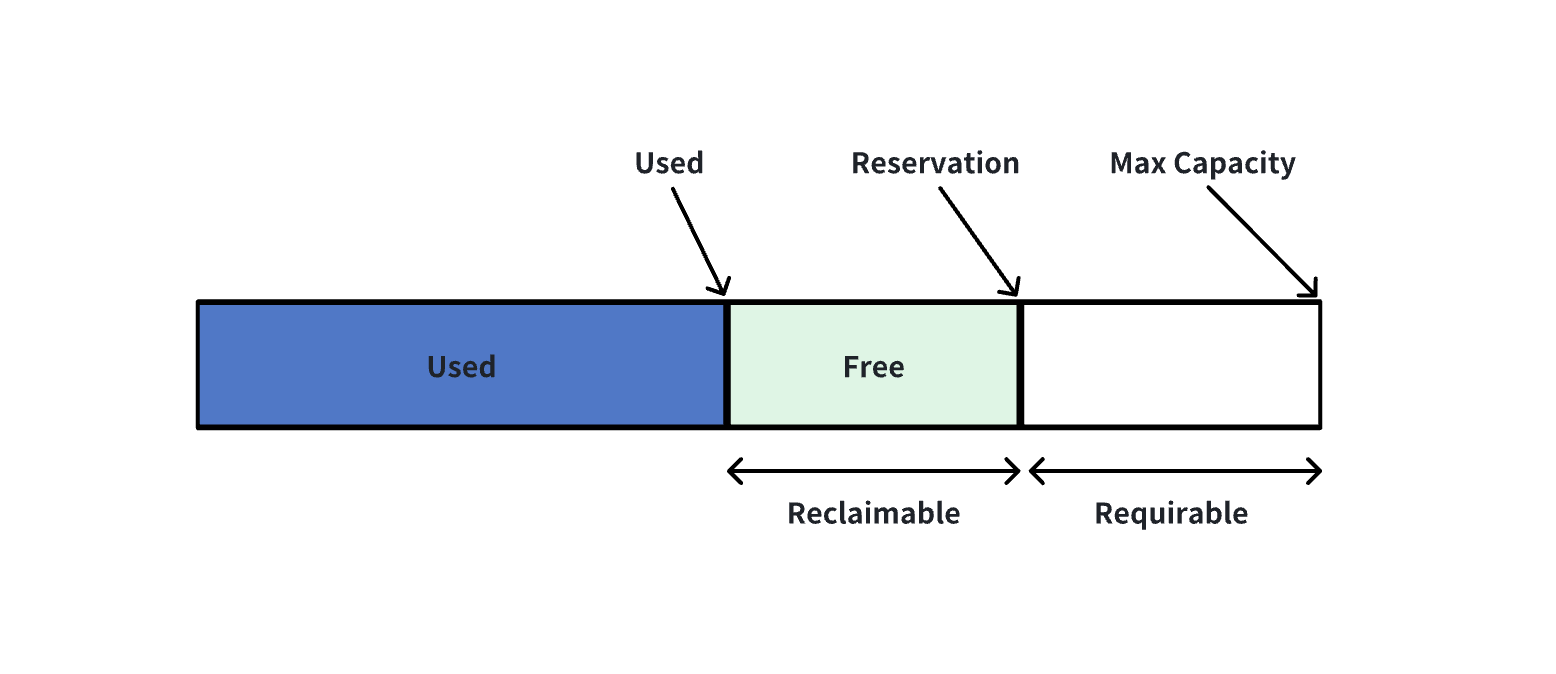
在每个 MemoryPool 中,都有一个容量(capacity)的概念,即每个池的最大容量是多少,当前已申请的容量是多少,以及当前所有的叶子节点在根池中获取的保留容量是多少。
- 例如,某个 leaf pool 需要申请新的内存,它将从绿色部分的容量中获取。若此容量不足,则需增长其容量以向右移。如果此时全局内存容量还是不够,会触发内存仲裁
内存仲裁的主要职责是管理所有 query 的可用容量,并在查询间进行仲裁。
- 决定将哪个查询,或查询中的哪个算子闲置的容量归还于该查询或算子
- 又或是通过 spill 技术,将bi操作符中使用的容量,使用的状态数据进行溢出处理后,将溢出的容量还回给查询。
一次内存仲裁是由某次内存分配请求触发的
- 如果内存分配请求到达 QueryPool 时发现内存不足,MemoryManager 会触发一次内存仲裁
- 内存仲裁本质上是一次内存回收,它将决定回收哪些查询的内存,以及怎么回收
- 假设已经选定了回收某个 Query 的内存,内存回收请求会自顶向下传递,直到叶子节点
- LocalArbitration
假设 QueryA 的 OperatorA 触发了一次仲裁,Local 策略只会回收 QueryA 内部的其他 Operator 闲置内存。
如 QueryA 下面的 OperatorA 需要内存,则会把 QueryA 内除了 OperatorA 的 free 内存都回收掉,分配给 OperatorA
- GlobalArbitration
假设 QueryA 触发了一次仲裁,Local 策略会尝试回收其他 Query 的闲置内存
- 过程同上
- 选择除了 QueryA 之外的某次 Query、比如 QueryB 进行回收
- 选择策略:Query 根据 free 内存大小进行排序,会选择 free 内存最大的 Query 进行回收
- 默认回收策略:只回收 free 部分的内存
Feature3: 并发安全与 OOM Handle Strategy
Design:
如果某次 Operator 请求分配内存,经过一次内存仲裁之后仍然内存不够,抛出 OOM 异常(自己定制的),中断本次查询任务(Abort 自己),释放所有内存。
要求:对于同一个 pool,内存仲裁、内存分配、内存去配三者都是串行,不允许两两并行。
- 内存仲裁时不允许分配或去配内存,因为内存仲裁的过程中要保证 Pool 的内存状态不可变。即内存仲裁时需要暂停 Query(不允许分配内存、去配内存)
- 该“暂停”不需要真正的暂停,因为我们只需要内存状态不变即可,不需要执行状态不变。
- 通过打标志位实现,发生仲裁后打上标记。
- 该 pool 如果后续在申请内存、释放内存时发现打上了标记,会在 condition wait(如此能实现 query 任务“暂停”的效果)。直到仲裁结束后唤醒(signal)
- 申请内存时,和内存仲裁共享一把锁,以保证内存仲裁和内存分配是串行的(不会并发)
- 内存池释放时,不允许和其他过程并发(分配、仲裁)
- 去配内存时,打上 closed 标记。不允许其他过程与 release 并发进行
Effect:
Feature4: 核心数据结构堆外改造
Design:
启发:观察了 dump 出来的文件,发现 90%以上的查询内存占用在:label、property、edge 和 vertex 上。查询过程的内存占用集中在少数、不可变、拥有大量实例的 class 上
内容:不把数据结构对象全改造成堆外的,还是让数据结构对象保持在堆内,只把其中内存占用大、不可变的某些成员变量,比如 label(本质上是个 int)存在堆外,然后内存管理框架管理这部分堆外内存
- 这些不可变的成员变量用堆外管理方便实现零拷贝读写

- 找出所有可以改造的【内存占用大】且【不可变】对象,提供从堆外直接访问读取的 API
- Object[]:主要内存占用来自于 HugeEdge 的 List,只要解决 HugeEdge 的改造即可
- HugeVertex:主要内存占用来自于 HugeEdge 的 List,只要解决 HugeEdge 的改造即可
- HugeEdge:
- 一部分来自于 id 的内存占用
- IdGenerator.Id:已完成改造
- 一部分来自于 IntObjectMap,该部分为可变的,无法改造
- 一部分来自于 id 的内存占用
- label:本质上就是 Id,只要完成了 Id 的改造即可
- HugeProperty:本质上是 value,将 value 存到堆外即可
- 实现了 Factory,使用 Factory 替换所有 new 上述对象的地方。
- Factory 的接口和原来 new 保持一致。
- Factory 内部根据用户设置的 memory_mode,选择构造原来的堆内版本对象还是构造堆外对象。